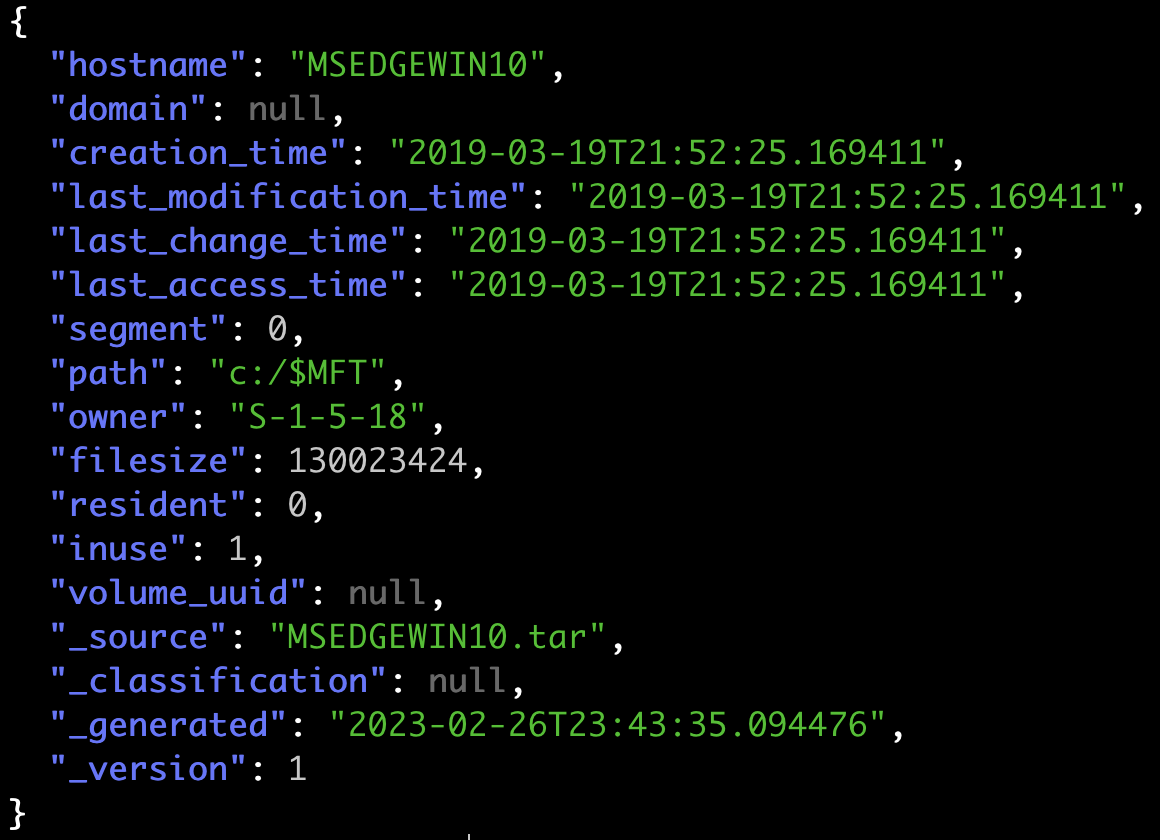
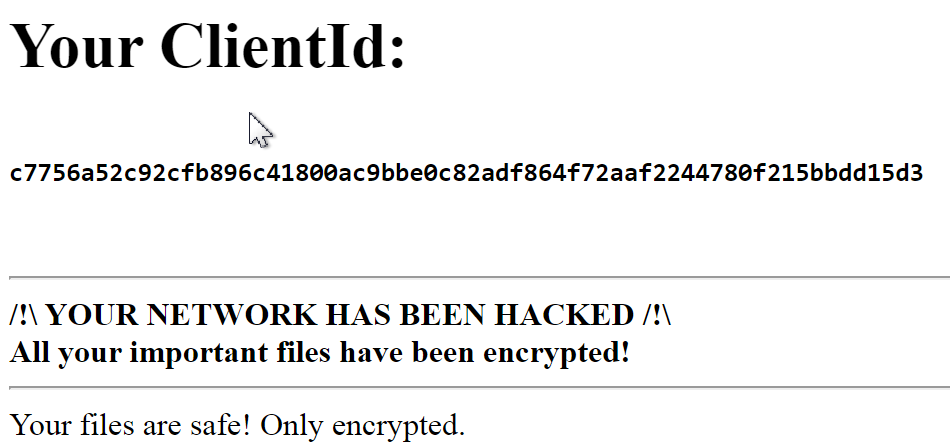
Automating DFIR using Cloud services
TL;DR: The DFIR lab can automate the processing of Plaso timelines to Timesketch using Velociraptor and Google Cloud services
As incident response (IR) cases become bigger so should the tooling used by Incident Responders to meet the growing needs. From my own experience during IR cases is that there is a demand for answers to research questions that can be answered by performing triage. The last thing you want to do as an Incident Responder during this phase is execute repetitive tasks by hand that are sensitive to errors and that can be automated.
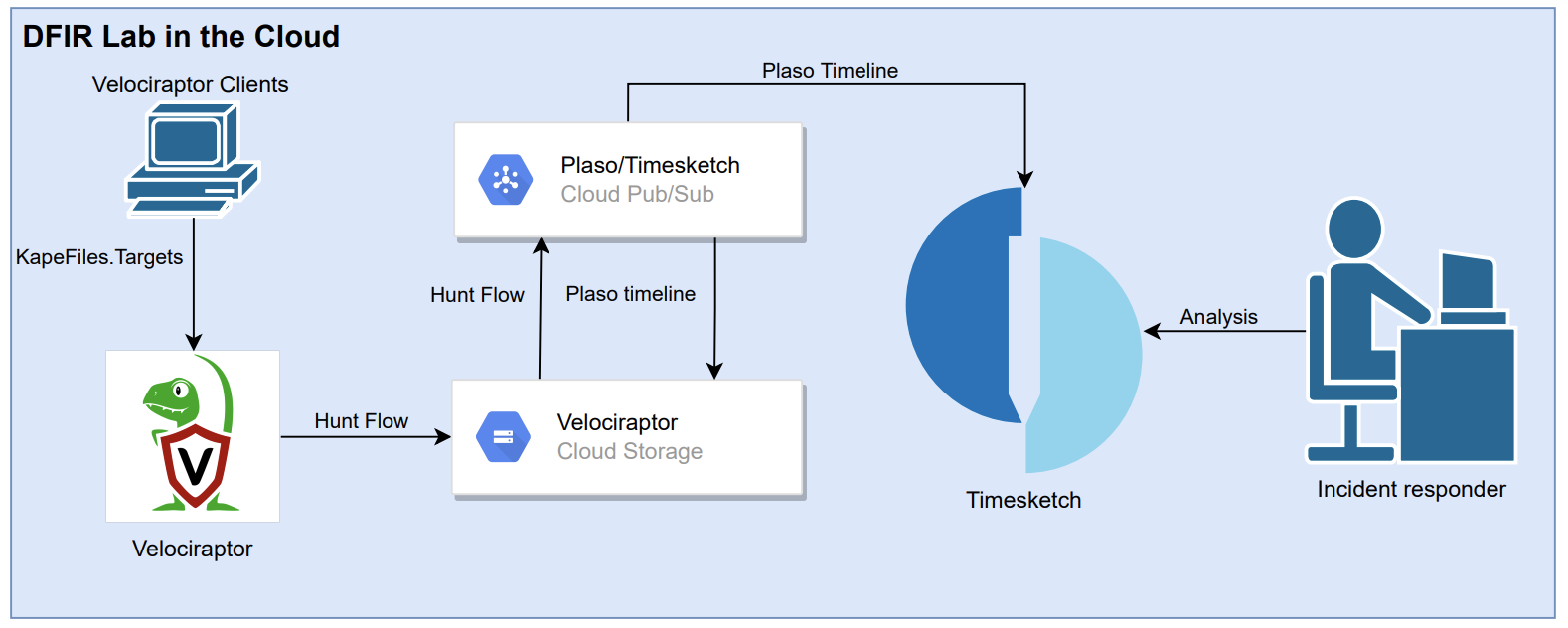
This brought me to the idea of using Cloud services to automate the processing of Plaso timelines from acquiring forensics artifacts until analysing. Normally I would execute the following flow of analysing a timeline. Using Velociraptor to acquire data from compromised systems, process the data with Plaso and analyse the timelines with Timeline Explorer a sort of Excel++.
But doing this for multiply systems, firewall logs and other sources is not possible on a single computer with the collaboration of colleagues, the correlation between timelines and possible automation possibilities. This is where Timesketch comes in which is a collaborative forensic timeline analysis tool. By combining Timesketch with the other tools, the DIFR lab is created based on the following flow:
Velociraptor (acquire) -> Plaso (process) -> Timesketch (analyse)
I hope this project can inspire other Incident Responders to use Cloud services and software to automate tasks during IR cases.
Incident Response at scale
We have the tools for the DFIR lab but how can we use those during an IR case that can scale fast from a handful of compromised systems to hundreds maybe even thousands. Because of that I chose Public Cloud as the infrastructure for the lab instead of creating playbooks to deploy the lab on an On-Premise infrastructure. I am a fan of the Google Cloud Platform (GCP) that’s why I am using their services to deploy this lab, but this project can also be created for AWS, Azure or any other Cloud provider with a variation of Cloud services.
To scale the use of the tools the lab takes advantage of the following benefits of the Public Cloud:
- Elasticity – The lab is made of microservices that can be scaled and work independently of each other;
- Scalability – The lab can be scaled based on the demands of the IR case;
- Availability – The resources are spread over multiply zones in a region and the Cloud provider is responsible for the availability of these zones and the Cloud services.
Translating the benefits of Public Cloud to the needs for an IR case gives the lab the following options to perform incident response at scale:
- Vertical - Upgrade the CPU or memory of systems to make processing faster;
- Horizontal - Use more systems to process data instead of upgrading a single system;
- Auto scaling - Based on the load of the systems the microservice should automatically use horizontal scaling (this is currently not implemented);
- Auto healing - If systems are not healthy they should automatically be stopped and recreated without noticeable problems by the user (this is currently not implemented);
- Storage - The possibility to use large amounts of storage without buying hardware (capital expense) which will not be used over time.
Components
The lab can be used by following the instructions:
- Hunt for compromised systems using various Velociraptor hunts;
- Acquire forensic artifacts of compromised systems with the Velociraptor artifact KapeFiles.Targets;
- In the background the hunt collections are parallel processed using Plaso;
- After processing the timeline is uploaded to Timesketch (Elasticsearch);
- The Incident Responder can analyse the timeline in Timesketch.
Thanks to all the contributors of Velociraptor, Plaso and Timesketch!
The Terraform configuration contains 84 Terraform resources. The Gitlab project contains all necessary steps to set up the lab at GCP.
Velociraptor hunting
Velociraptor is an advanced digital forensic and incident response tool that enhances your visibility into your endpoints.
Collect - At the press of a (few) buttons, perform targeted collection of digital forensic evidence simultaneously across your endpoints, with speed and precision.
Monitor - Continuously collect endpoint events such as event logs, file modifications and process execution. Centrally store events indefinitely for historical review and analysis.
Hunt - Don’t wait until an event occurs. Actively search for suspicious activities using our library of forensic artifacts, then customize to your specific threat hunting needs. - https://docs.velociraptor.app/
The reasons why I like using Velociraptor:
- Open source and cross-platform (Windows, Linux and Mac);
- The installation is quick and easy;
- Velociraptor performs parsing and analysis on the clients instead of the server, this makes a huge difference with thousands of clients;
- The hunts only download the data needed to perform analysis instead of acquiring full disks.
The following steps can be performed during an IR case to collect forensics artifacts from compromised systems:
- Create a hunt with the artifact
Windows.KapeFiles.Targetsincluding the parameterSANS Triage Collectionand the labelcompromised; - Identify compromised systems by executing additional Velociraptor hunts. For example use
Windows.Search.FileFinderto search for ransom notesC:\*.txt". - Add the label
compromisedto the systems that contain traces of an attacker; - The already created hunt will collect the artifact
Windows.KapeFiles.Targetsfrom the systems and the server event monitoringServer.Utils.BackupGCSsaves these to a Google Cloud Storage bucket for every system.
The setup of Velociraptor is shown below:
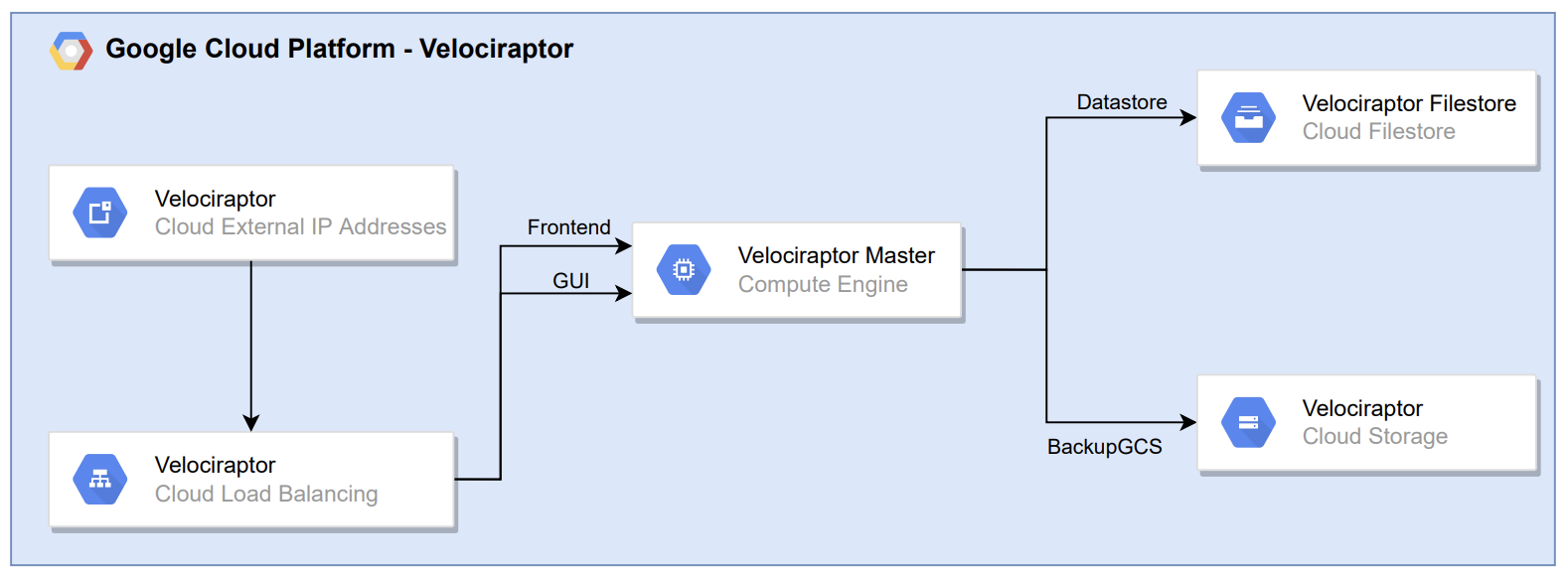
Scaling options:
- Adjust the instance type (CPU and memory) used by Velociraptor;
- Adjust the Filestore tier;
- Add Velociraptor minions which can take care of the Frontend backend service by implementing multi-frontend.
Processing (Pub/Sub)
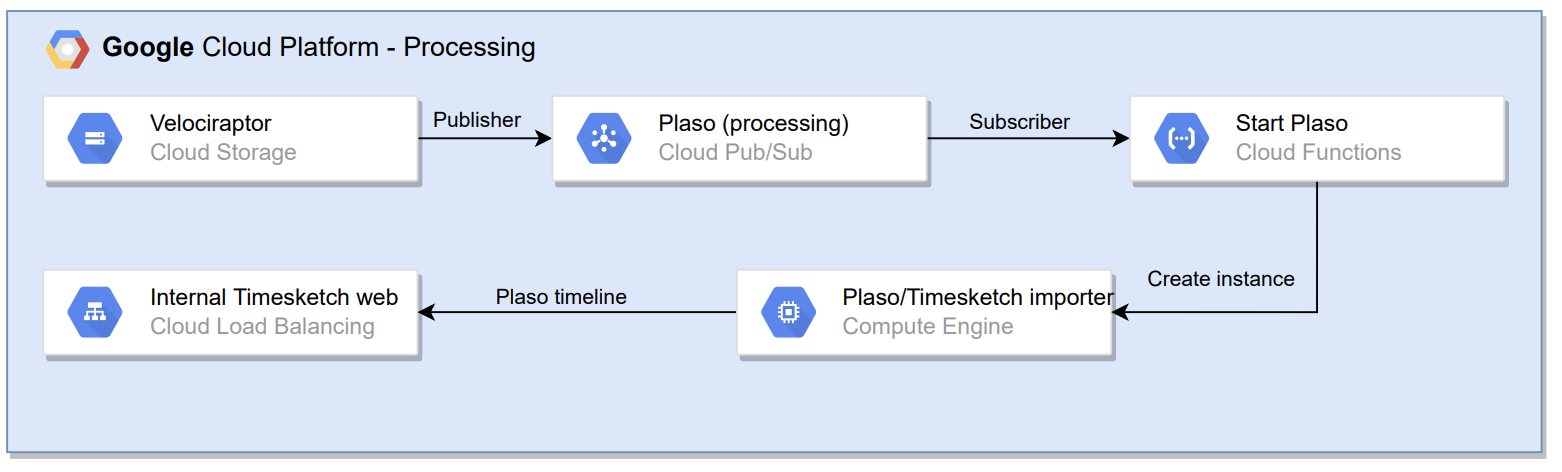
Now that the hunt collections are uploaded to a Googe Cloud storage bucket those need to be processed by using Plaso.
- For every hunt collection uploaded to the bucket (publisher) an object notification is sent to the topic
plaso; - This triggers the execution of Cloud Function (subscriber) that starts a VM instance that will process the hunt collection with Plaso;
- After the VM instance is done processing the Plaso timeline is uploaded to the bucket as back-up and to Timesketch using the Timesketch importer;
- After the uploading is finished the VM instance deletes itself (saves costs).
The steps above are all executed parallel for every hunt collection. This way the processing of different hunt collections doesn’t get in each other’s way.
Below the flow of Velociraptor hunt collection to Timesketch is shown:
Scaling option:
- Adjust the instance type (CPU and memory) used by Plaso.
Timesketch
Timesketch is an open-source tool for collaborative forensic timeline analysis. Using sketches you and your collaborators can easily organize your timelines and analyze them all at the same time. Add meaning to your raw data with rich annotations, comments, tags and stars. - https://timesketch.org/
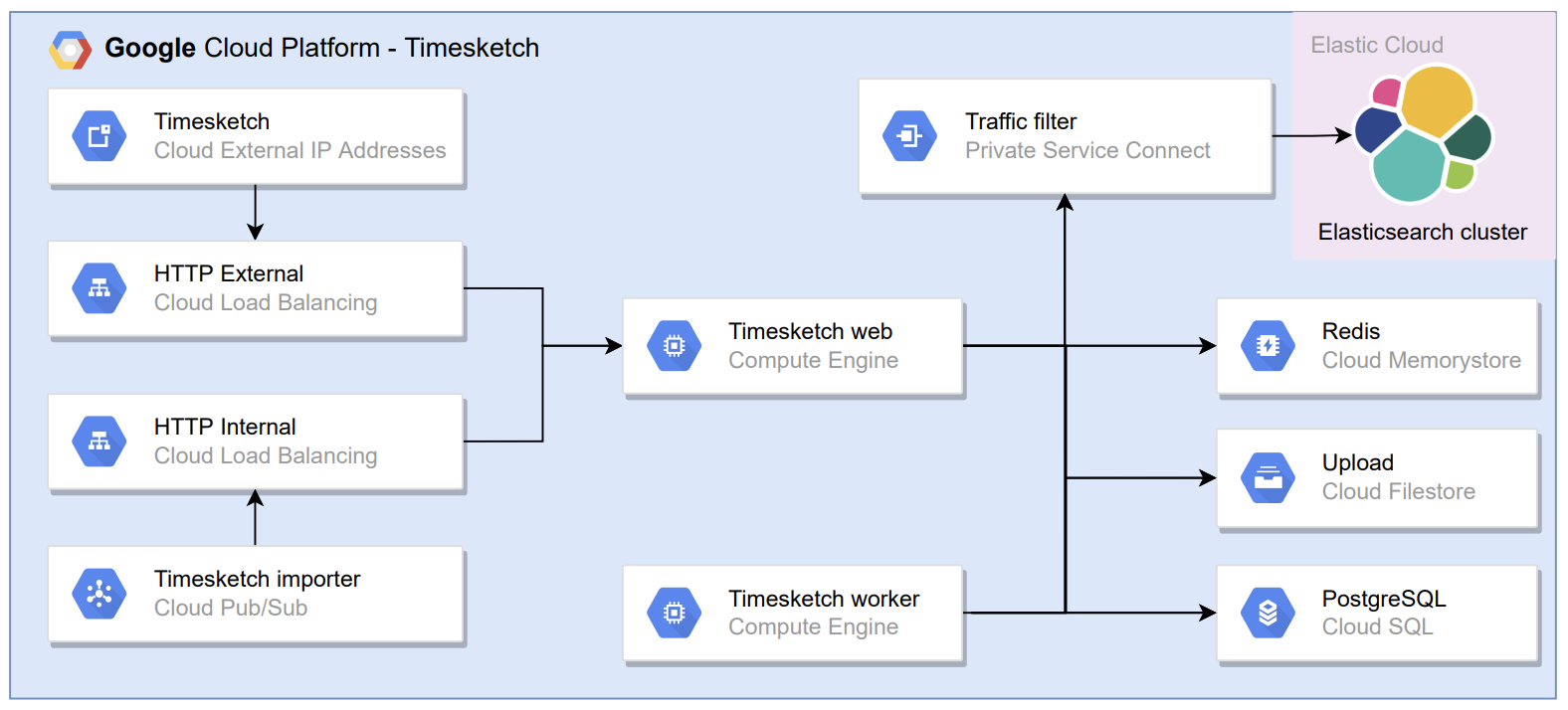
- After the Timesketch importer uploads the Plaso timelines to the Filestore. The Timesketch workers are notified about new tasks that can be executed;
- Using the output module to Elasticsearch the Timesketch workers use
psort.py(Plaso) to upload the timelines to Elasticsearch. - After the upload is finished the Incident Responder can analyse the timelines and use Timesketch analyzers to automate investigation steps.
Instead of using VM instances to host Elasticsearch, I chose to use Elastic Cloud. Which is a SaaS service that can be used in GCP using a Private Service Connect.
Below the Timesketch setup is shown:
Scaling options:
- Adjust the instance types (CPU and memory) used by the Timesketch web and worker VM instances, Elasticsearch, PostgreSQL or Redis;
- Increase the target size of the backend services timesketch-web and timesketch-worker to scale up;
- Adjust the Filestore tier.
Sigma analyzer
Sigma is a generic and open signature format that allows you to describe relevant log events in a straightforward manner. The rule format is very flexible, easy to write and applicable to any type of log file. The main purpose of this project is to provide a structured form in which researchers or analysts can describe their once developed detection methods and make them shareable with others.
Sigma is for log files what Snort is for network traffic and YARA is for files. - https://github.com/SigmaHQ/sigma
Timesketch can convert Sigma rules to Elasticsearch queries using the Sigma analyzer. This way detection rules can analyse timelines and annotate events based on Tactics, Techniques and Procedures (TTPs) from any APT you are investigating. This will maybe not give a direct answer to research questions during an IR case but can detect low hanging fruit which speeds up the identification phase.
Future work
The project is not quite ready to use in production. I created this lab using free student GCP credits using a single Velociraptor client. Next to that the README contains a list of known issue’s that need to be fixed before using this project in production.
So to summarise the reasons I created this lab:
- Humans make mistakes and sometimes forget things. Nobody likes to check attack paths by hand which a detection rule can do;
- Computing power of Public Cloud services can reduce the time needed to set up storage and processing power;
- I am lazy and like to automate manual steps.
Eventually, nobody wants to be the person below not using computers for what they are made to do: